Click here and press the right key for the next slide (or swipe left)
also ...
Press the left key to go backwards (or swipe right)
Press n to toggle whether notes are shown (or add '?notes' to the url before the #)
Press m or double tap to slide thumbnails (menu)
Press ? at any time to show the keyboard shortcuts
\section{Background}
Knowledge of objects depends on abilities to (i) segment objects, (ii) represent them as
persisting and (iii) track their interactions.
\emph{Question 1} When do humans come to meet the three requirements on knowledge of objects?
\emph{Discovery 1} Infants manfiest all three abilities from around four months of age or earlier.
\emph{Question 2} How do humans come to meet the three requirements on knowledge of objects?
\emph{Discovery 2} Although abilities to segment objects, to represent them as persisting through
occlusion and to track their causal interactions are conceptually distinct, they
are all characterised by the Principles of Object Perception and they may all be
consequences of a single mechanism.
\emph{Question 3} What is the relation between the model specified by the Principles of Object
Perception and the infants?
\textit{The simple view}
The principles of object perception are things that we know or believe,
and we generate expectations from these principles by a process of inference.
The \emph{Core Knowledge View}
The principles of object perception are not
knowledge, but they are core knowledge. And we generate expectations from
these principles by a process of inference.
\emph{Discovery 3} The Simple View generates systematically false predictions.
(And the Core Knowledge View generates no relevant predictions by itself.)
\emph{Question 4} What is the relation between adults’ and infants’ abilities concerning physical
objects and their causal interactions?
When and how do humans first come to know simple facts about particular physical objects?
The question for this course is ...
Our current question is about physical objects.
How do humans first come to know simple facts about particular physical objects?
In attempting to answer this question, we are focussing on the abilities of
infants in the first six months of life.
We are still on the when? question
What have we found so far? ...
What have we found so far?
Here’s what we’ve found so far.
We examined how three requirements on having knowledge of physical objects are met.
Knowledge of objects depends on abilities to (i) segment objects, (ii) represent them as
persisting and (iii) track their interactions.
To know simple facts about particular physical objects you need, minimally,
to meet these three requirements.
Three requirements
- segment objects
- represent objects as persisting (‘permanence’)
- track objects’ interactions
The second discovery concerned how infants meet these three requirements this.
Principles of Object Perception
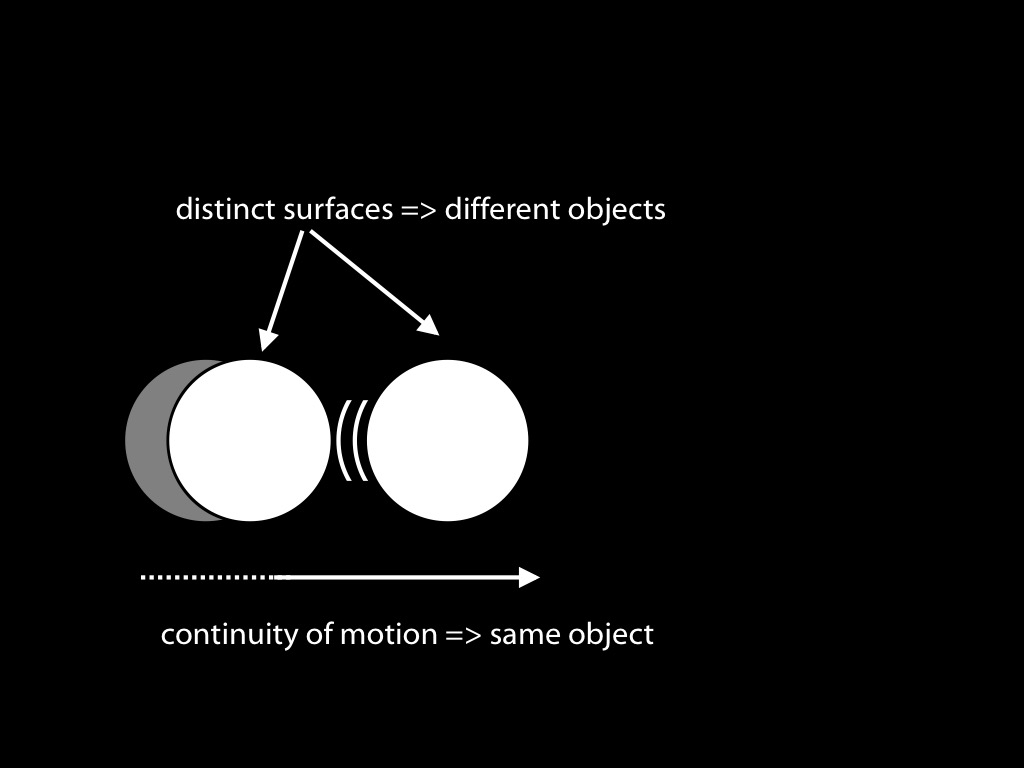
- cohesion—‘two surface points lie on the same object only if the points are linked by a path of connected surface points’
- boundedness—‘two surface points lie on distinct objects only if no path of connected surface points links them’
- rigidity—‘objects are interpreted as moving rigidly if such an interpretation exists’
- no action at a distance—‘separated objects are interpreted as moving independently of one another if such an interpretation exists’
Spelke, 1990
The second was that a single set of principles is formally adequate to
explain how someone could meet these requirements, and to describe
infants' abilities with segmentation, representing objects as persisting
and tracking objects' interactions.
This is exciting in several ways.
\begin{enumerate}
\item That infants have all of these abilities.
\item That their abilities are relatively sophisticated: it doesn’t seem
that we can characterise them as involving simple heuristics or relying
merely on featural information.
\item That a single set of principles underlies all three capacities.
\end{enumerate}
three requirements, one set of principles
three requirements, one set of principles: this suggests us that infants’
capacities are characterised by a model of the physical.
Three Questions
1. How do four-month-old infants model physical objects?
2. What is the relation between the model and the infants?
3. What is the relation between the model and the things modelled (physical objects)?
[slide: model]
three requirements, one set of principles: this suggests us that infants’
capacities are characterised by a model of the physical (as opposed to
being a collection of unrelated capacities that only appear, but don’t
really, have anything to do with physical objects).
1. How do four-month-old infants model physical objects?
In asking how infants
model physical objects, we are seeking to understand not how physical objects
in fact are but how they appear from the point of view of
an individual or system.
The model need not be thought of as something used by the system: it is
a tool the theorist uses in describing what the system is for and
broadly how it works.
This therefore leads us to a second question ...
2. What is the relation between the model and the infants?
3. What is the relation between the model and the things modelled (physical objects)?
What have we found so far? ... Apparently conflicting evidence.
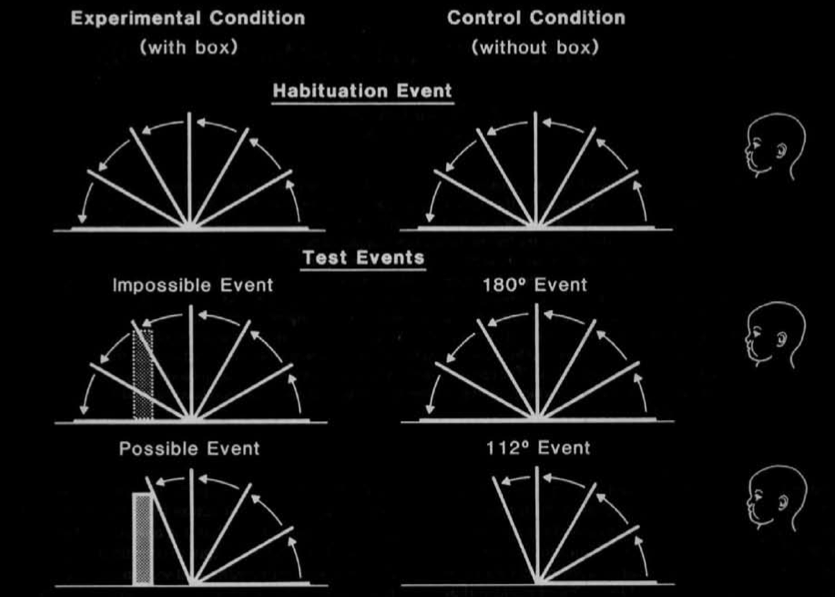
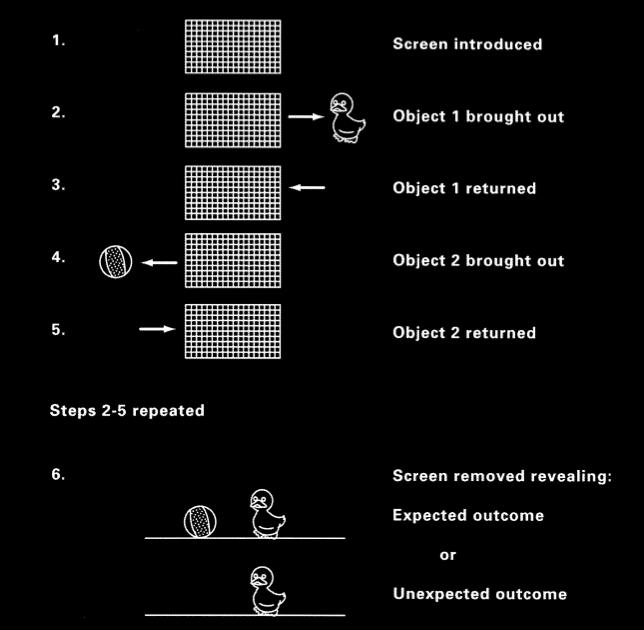
Baillargeon et al 1987, figure 1
Shinskey and Munakata 2001, figure 1
More than two decades of research strongly supports the view that
infants fail to search for objects hidden behind barriers or screens
until around eight months of age \citep[p.\ 202]{Meltzoff:1998wp} or
maybe even later \citep{moore:2008_factors}.
Researchers have carefully controlled for the possibility that infants’
failures to search are due to extraneous demands on memory or the
control of action.
We must therefore conclude, I think, that four- and five-month-old
infants do not have beliefs about the locations of briefly occluded
objects.
It is the absence of belief that explains their failures to search.
| | occlusion | endarkening |
| violation-of-expectations | ✔ | ✘ |
| manual search | ✘ | ✔ |
Charles & Rivera (2009)
Recall the puzzle ....
the discrepancy in looking vs search measures.
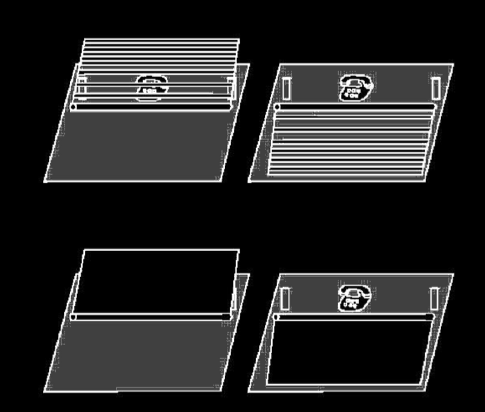
Spelke et al 1992, figure 2

Hood et al 2003, figure 1
Three Questions
1. How do four-month-old infants model physical objects?
2. What is the relation between the model and the infants?
3. What is the relation between the model and the things modelled (physical objects)?
[slide: model]
three requirements, one set of principles: this suggests us that infants’
capacities are characterised by a model of the physical (as opposed to
being a collection of unrelated capacities that only appear, but don’t
really, have anything to do with physical objects).
Two Candidate Answers to Q2
the Simple View ... generates incorrect predictions
the Core Knowledge View ... generates no relevant predictions
Let’s build on the simple view, extending it so that we do generate
relevant predictions.
(There were also theoretical objections: maybe we can overcome these
by extending it too.)

The CLSTX Hypothesis: Object Indexes Underpin Infants’ Abilities
\section{The CLSTX Hypothesis: Object Indexes Underpin Infants’ Abilities}
Three requirements
- segment objects
- represent objects as persisting (‘permanence’)
- track objects’ interactions
How? Object Indexes!
In adult humans,
there is a system of object indexes which enables them to track
potentially moving objects in ongoing actions such as visually tracking or
reaching for objects, and which influences how their attention is allocated
\citep{flombaum:2008_attentional}.
The leading, best defended hypothesis is that their abilities to do so
depend on a system of
object indexes like that which underpins multiple object tracking or
object-specific preview benefits
\citep{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta}.
But what is an object index?
Formally, an object index is ‘a mental token that functions as a
pointer to an object’ \citep[p.\ 11]{Leslie:1998zk}.
If you imagine using your fingers to track moving objects,
an object index is the mental counterpart of a finger \citep[p.~68]{pylyshyn:1989_role}.
Leslie et al say an object index is ‘a mental token that functions as a pointer to an
object’ \citep[p.\ 11]{Leslie:1998zk}
‘Pylyshyn’s FINST model: you have four or five indexes which can be attached to objects;
it’s a bit like having your fingers on an object: you might not know anything about the
object, but you can say where it is relative to the other objects you’re fingering.
(ms. 19-20)’ \citep{Scholl:1999mi}
The interesting thing about object indexes is that a system of object
indexes (at least one, maybe more)
appears to underpin cognitive processes which are not
strictly perceptual but also do not involve beliefs or knowledge states.
While I can’t fully explain the evidence for this claim here,
I do want to mention the two basic experimental tools that are used to
investigate the existence of, and the principles underpinning,
a system of object indexes which operates
between perception and thought ...
Object indexes ...
\begin{itemize}
\item guide ongoing action (e.g.~visual tracking, reaching)
\item influence how attention is allocated
\citep{flombaum:2008_attentional}
\item can be assigned in ways incompatible with beliefs and knowledge \citep[e.g.][]{Mitroff:2004pc, mitroff:2007_space}
\item have behavioural and neural markers, in adults and infants \citep{richardson:2004_multimodal,kaufman:2005_oscillatory}.
\item are subject to signature limits \citep[pp.~83--87]{carey:2009_origin}
\item sometimes survive occlusion \citep{flombaum:2006_temporal}
\end{itemize}
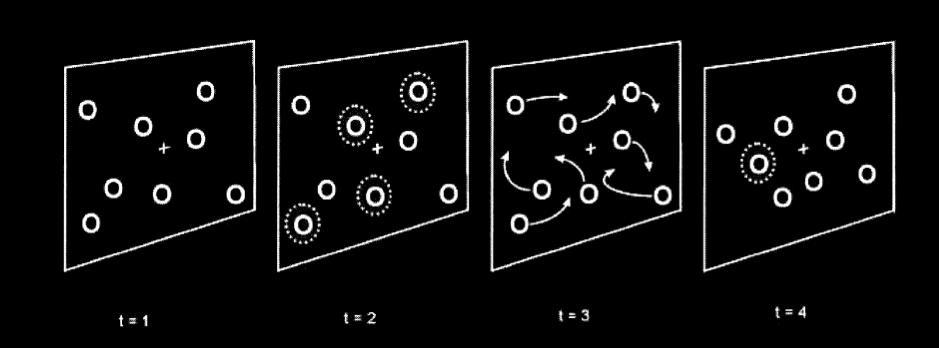
Suppose you are shown a display involving eight stationary circles, like
this one.
Four of these circles flash, indicating that you should track these circles.
All eight circles now begin to move around rapidly, and keep moving unpredictably for some time.
Then they stop and one of the circles flashes.
Your task is to say whether the flashing circle is one you were supposed to track.
Adults are good at this task \citep{pylyshyn:1988_tracking}, indicating that they can use at least four object indexes simultaneously.
(\emph{Aside.} That this experiment provides evidence for the existence of
a system of object indexes has been challenged.
See \citet[p.\ 59]{scholl:2009_what}:
\begin{quote}
`I suggest that what Pylyshyn’s (2004) experiments show is exactly what they intuitively
seem to show: We can keep track of the targets in MOT, but not which one is which.
[...]
all of this seems easily explained [...] by the view
that MOT is simply realized by split object-based attention to the MOT targets as a set.'
\end{quote}
It is surely right that the existence of MOT does not, all by itself,
provide support for the existence of a system of object indexes.
However, contra what Scholl seems to be suggesting here, the MOT paradigm
can be adapated to provide such evidence.
Thus, for instance, \citet{horowitz:2010_direction} show that, in a MOT paradigm, observers
can report the direction of one or two targets without advance knowledge of which
targets' directions they will be asked to report.)
Pylyshyn 2001, figure 6
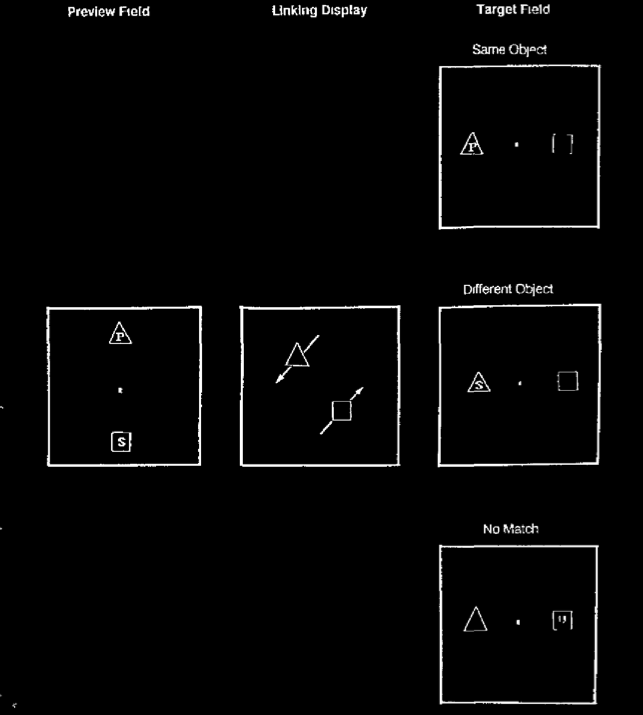
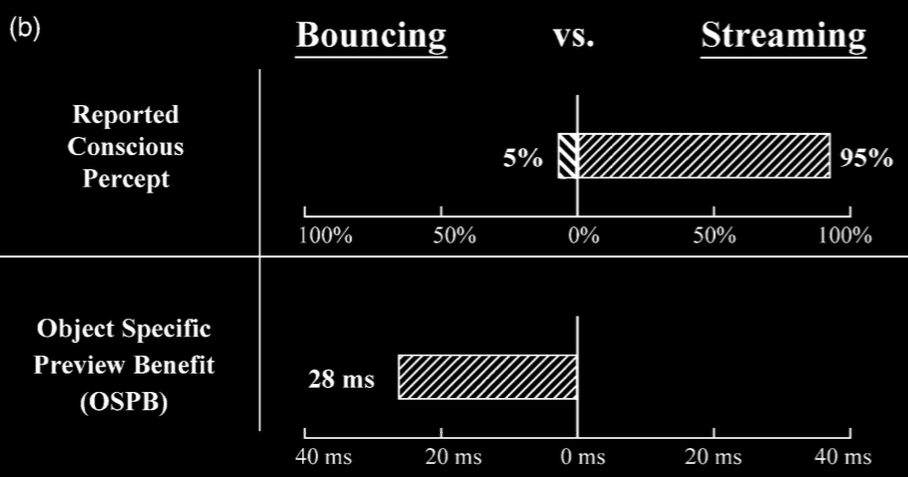
There is a behavioural marker of object-indexes called the object-specific preview benefit.
Suppose that you are shown an array of two objects, as depicted here.
At the start a letter appears briefly on each object.
(It is not important that letters are used; in theory, any readily
distinguishable features should work.)
The objects now start moving.
At the end of the task, a letter appears on one of the objects.
Your task is to say whether this letter is one of the letters that appeared at the start or whether it is a new letter.
Consider just those cases in which the answer is yes: the letter at the end is one of those which you saw at the start.
Of interest is how long this takes you to respond in two cases: when the letter appears on the same object at the start and end, and, in contrast, when the letter appears on one object at the start and a different object at the end.
It turns out that most people can answer the question more quickly in the first case.
That is, they are faster when a letter appears on the same object twice than when it appears on two different objects
\citep{Kahneman:1992xt}.
This difference in response times is the
% $glossary: object-specific preview benefit
\emph{object-specific preview benefit}.
Its existence shows that, in this task, you are keeping track of which object is which as they move.
This is why the existence of an object-specific preview benefit is taken to be evidence that object indexes exist.
Kahneman et al 1992, figure 3
The \emph{object-specific preview benefit} is the reduction in time needed to identify that a
letter (or other feature) matches a target presented earlier when the letter and target both
appear on the same object rather than on different objects.
Three requirements
- segment objects
- represent objects as persisting (‘permanence’)
- track objects’ interactions
How? Object Indexes!
ok, so now we know what object indexes are ...
Why think that they answer the question How?
First part of the answer: maintaining object indexes requires all three things!
What is required for assigning and maintaining object indexes?
To see the need for principles,
return to the old-fashioned logistician who is keeping track of supply trucks.
In doing this she has only quite limited information to go on.
She receives sporadic reports that a supply truck has been sighted at one or another location.
But these reports do not specify which supply truck is at that location.
She must therefore work out which pin to move to the newly reported location.
In doing this she might rely on assumptions about the trucks’ movements being constrained to trace continuous paths, and about the direction and speed of the trucks typically remaining constant.
These assumptions allow her to use the sporadic reports that some truck or other is there in forming views about the routes a particular truck has taken.
A system of object indexes faces the same problem when the indexed objects are not continuously perceptible.
What assumptions or principles are used to determine whether this object at time $t_1$ and that object at time $t_2$ have the same object index pinned to them?

[object indexes and segmentation: ducks picture]
Is one object index assigned or two?
Assigning object indexes requires segmentation.
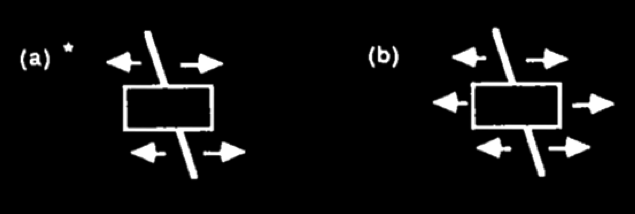
[object indexes and segmentation: partially occluded stick]
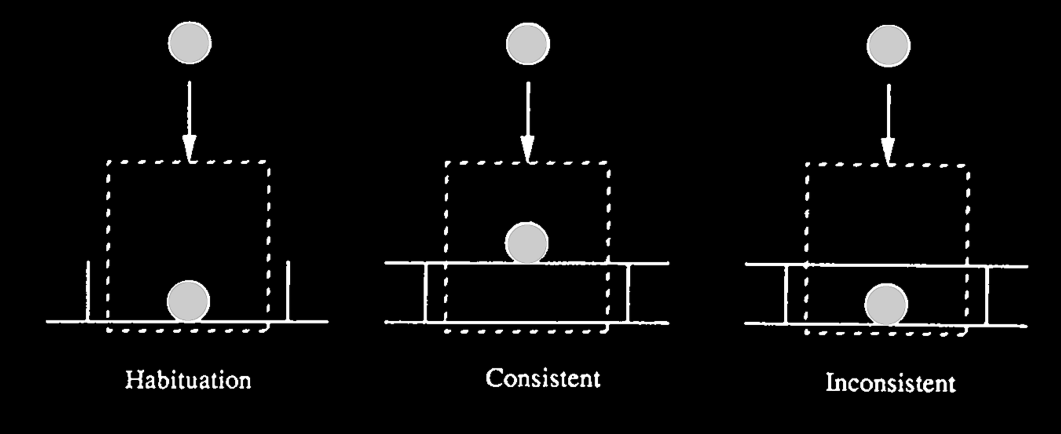
Spelke, 1990 figure 2a
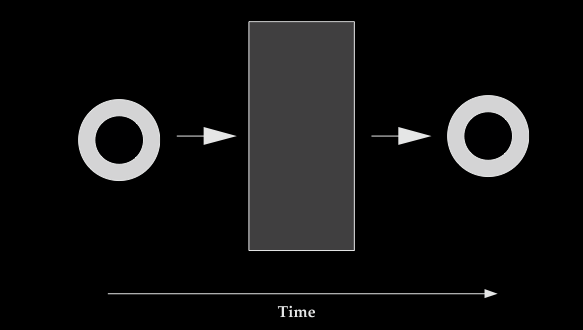
Consider a stick moving behind a screen, so that the middle part of it is occluded.
Assigning one index even though there is no information about continuity of surfaces
may depend on analysis of motion.
maintaining object indexes
involves
segmenting objects
representing them as perstising
tracking their causal interactions
knowledge of objects
involves
segmenting them
representing them as perstising
tracking their causal interactions
object indexes can survive brief occlusion
modified from Scholl 2007, figure 4
[object indexes and representing occluded objects]
principle of continuity---
an object traces exactly one connected path over space and time
Franconeri et at, 2012 figure 2a (part)
[Here we’re interested in the issue rather than the details: the point is just that
continuity of motion is important for assigning and maintaining object indexes.]
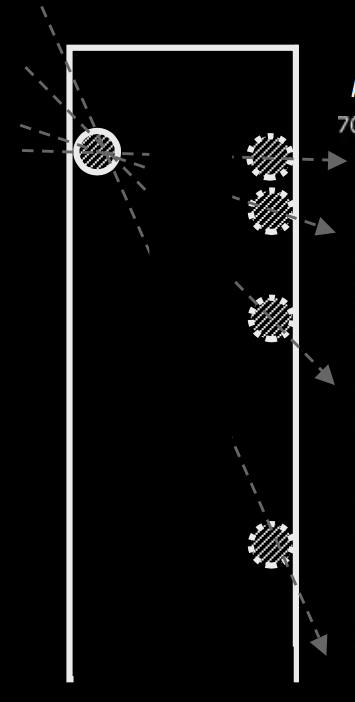
Suppose object indexes are being used in tracking four or more objects simultaneously and one of these objects—call it the \emph{first object}—disappears behind a barrier.
Later two objects appear from behind the barrier, one on the far side of the barrier (call this the \emph{far object}) and one close to the point where the object disappeared (call this the \emph{near object}).
If the system of object indexes relies on assumptions about speed and direction of movement, then the first object and the far object should be assigned the same object index.
But this is not what typically happens.
Instead it is likely that the first object and the near object are assigned the same object index.%
\footnote{
See \citet{franconeri:2012_simple}. Note that this corrects an earlier argument for a contrary view \citep{scholl:1999_tracking}.
}
If this were what always happened, then we could not fully explain how infants represent objects as persisting by appeal to object indexes because, at least in some cases, infants do use assumptions about speed and direction in interpolating the locations of briefly unperceived objects.
There would be a discrepancy between the Principles of Object Perception which characterise how infants represent objects as persisting and the principles that describe how object indexes work.
But this is not the whole story about object indexes.
It turns out that object indexes behave differently when just one object is being tracked and the object-specific preview benefit is used to detect them.
In this case it seems that assumptions about continuity and constancy in speed and direction do play a role in determining whether an object at $t_1$ and an object at $t_2$ are assigned the same object indexes \citep{flombaum:2006_temporal,mitroff:2007_space}.
In the terms introduced in the previous paragraph, in this case where just one object is being tracked, the first object and the far object are assigned the same object index.
This suggests that the principles which govern object indexes may match the principles which characterise how infants represent objects as persisting.
maintaining object indexes
involves
segmenting objects
representing them as perstising
tracking their causal interactions
knowledge of objects
involves
segmenting them
representing them as perstising
tracking their causal interactions
[object indexes and representing causal interactions]
maintaining object indexes
involves
segmenting objects
representing them as perstising
tracking their causal interactions
knowledge of objects
involves
segmenting them
representing them as perstising
tracking their causal interactions
The Principles of Object Perception are the key to specifying one way
of meeting these three requirements.
This suggests that, maybe,
The Principles of Object Perception which characterise infants’ abilities to track
physical objects also characterise the operations of a system of object indexes.
\emph{The CLSTX conjecture}
Five-month-olds’ abilities to track occluded objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
object indexes.
\citep{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta}.
The CLSTX conjecture:
Five-month-olds’ abilities to track briefly unperceived objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
a system of object indexes.
Leslie et al (1989); Scholl and Leslie (1999); Carey and Xu (2001)
(‘CLSTX’ stands for Carey-Leslie-Scholl-Tremoulet-Xu \citep[see][]{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta})
Their upshot is not knowledge about particular objects and their movements but rather a
perceptual representation involving an object index.
One reason the hypothesis seems like a good bet is that object
indexes are the kind of thing which could in principle explain
infants’ abilities to track unperceived objects because object indexes
can, within limits, survive occlusion.
Note that the CLSTX conjecture assumes that
the Principles of Object Perception which characterise infants’ abilities to track
physical objects also characterise the operations of a system of object indexes.
:treflecting on \citet{mccurry:2009_beyond} in one of the seminars ... distinguishedinitiating action and continuing to perform an action ... object indexes supportguidance of action but not its initiation.
This amazing discovery is going to take us a while to fully digest. As a first step, note its
significance for Davidson's challenge about characterising what is going on in the head of the
child who has a few words, or even no words.
\footnote{\label{fn:mot_proximity}
The findings cited in this paragraph all involve measuring object-specific preview benefits.
Some researchers have argued that in multiple object tracking with at least four objects,
motion information is not used to update indexes during the occlusion of the corresponding objects \citep{keane:2006_motion,horowitz:2006_how}; rather, `MOT through occlusion seems to rely on a simple heuristic based only on the proximity of reappearance locations to the objects’ last known preocclusion locations' (\citealp{franconeri:2012_simple}, p.\ 700).
However information about motion is sometimes available \citep{horowitz:2010_direction} and used in tracking multiple objects simultaneously \citep{howe:2012_motion, clair:2012_phd}.
One possibility is that, in tracking four objects simultaneously, motion information can be used to distinguish targets from distractors but not to predict the future positions of objects \citep[p.\ 8]{howe:2012_motion}.
}
Three Questions
1. How do four-month-old infants model physical objects?
2. What is the relation between the model and the infants?
3. What is the relation between the model and the things modelled (physical objects)?
2. What is the relation between the model and the infants?
Candidate Answers to Q2
the Simple View ... generates incorrect predictions
the Core Knowledge View ... generates no relevant predictions
Why doesn’t the CLSTX generate the same incorrect predictions as the Simple View?
... Because object index assignments can conflict with knowledge states!
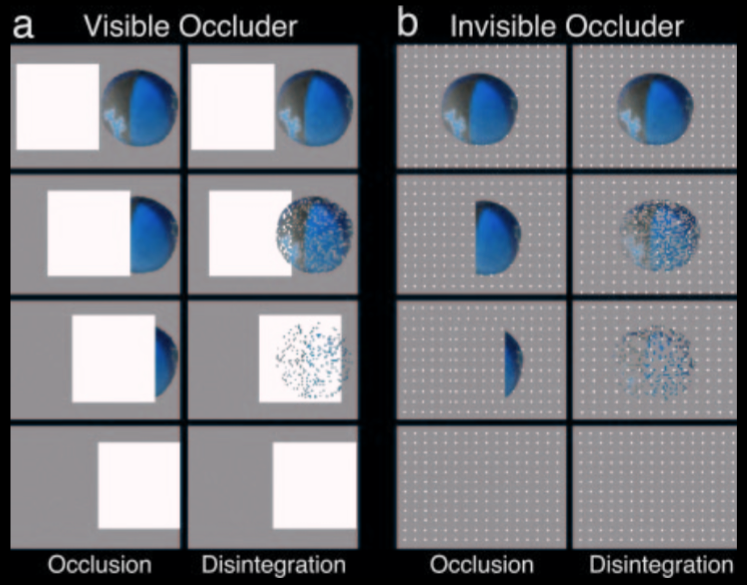
Scholl 2007, figure 4
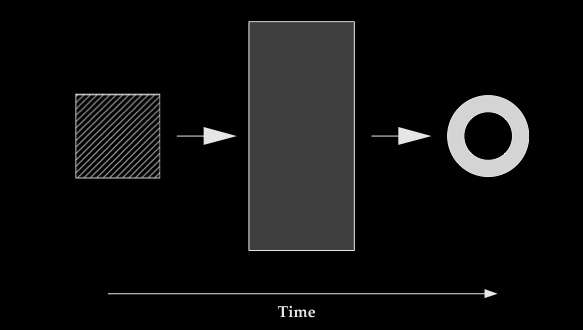
Consider this scenario
in which a patterned square disappears behind the barrier; later a
plain black ring emerges. You probably don't believe that they are
the same object, but they probably do get assigned the same object index.
Your beliefs and assignments of object indexes are inconsistent in this
sense: the world cannot be such that both are correct.
The CLSTX Conjecture has an advantage which I don’t think is widely recognised.
This is that object indexes are independent of beliefs and knowledge
states.
Having an object index pointing to a location is not the same thing
as believing that an object is there.
And nor is having an object index pointing to a series of locations over time
is the same thing as believing or knowing that these locations
are points on the path of a single object.
Further, the assignments of object indexes do not invariably give rise
to beliefs and need not match your beliefs.
Mitroff, Scholl and Wynn 2005, figure 2
Mitroff, Scholl and Wynn 2005, figure 3
So this is a virtue of the hypothesis that four- and five-month-old
infants’ abilities
to track briefly occluded objects depend on a system of
object indexes.
Since assignments of object indexes do not entail the existence of
corresponding beliefs,
the fact that infants of this age systematically
fail to search for briefly occluded objects is not an objection to the
hypothesis.
Three Questions
1. How do four-month-old infants model physical objects?
2. What is the relation between the model and the infants?
3. What is the relation between the model and the things modelled (physical objects)?
Candidate Answers to Q2
the Simple View ... generates incorrect predictions
the Core Knowledge View ... generates no relevant predictions
the CLSTX Conjecture
behavioural and neural indicators
behavioural: OSPB-like-effect (Richardson & Kirkham; note their caveats); neural Kaufmann, Csibra
et al
If we consider six-month-olds, we can also find behavioural markers
of object indexes in infants \citep{richardson:2004_multimodal} ...
... and there are is also a report of neural markers too \citep{kaufman:2005_oscillatory}.
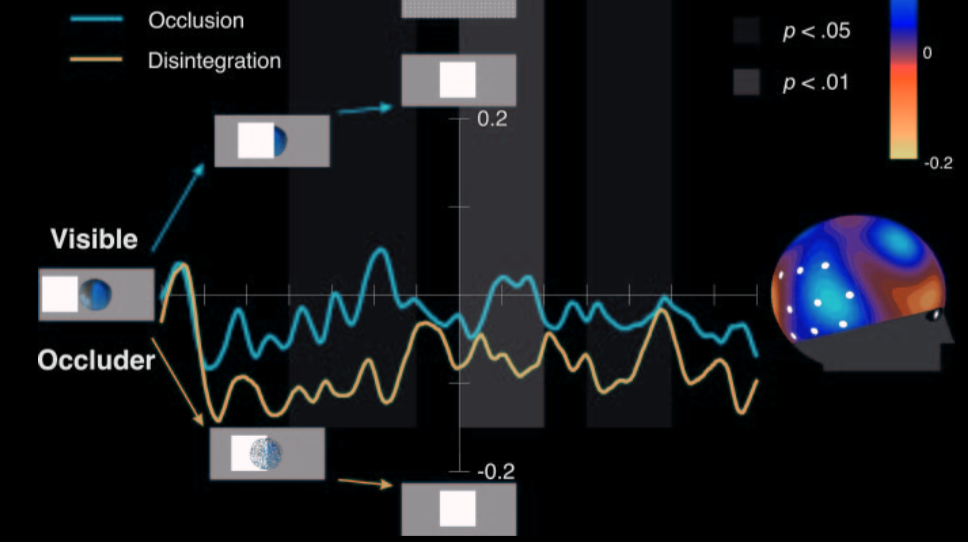
Kaufmann et al, 2015 figure 1
(\citet{kaufman:2005_oscillatory} measured brain activity in
six-month-olds infants as they observed a display typical of an object
disappearing behind a barrier.
(EEG gama oscillation over right temporal cortex)
They found the pattern of brain activity characteristic of maintaining
an object index.
This suggests that in infants, as in adults, object indexes can attach
to objects that are briefly unperceived.)
Kaufmann et al, 2015 figure 2 (part)
The evidence we have so far gets us as far as saying, in effect, that someone capable of
committing a murder was in the right place at the right time.
Can we go beyond such circumstantial evidence?
Signature Limits
The key to doing this is to exploit signature limits.
A \emph{{signature limit} of a system} is a pattern of behaviour the system exhibits which is
both defective given what the system is for and peculiar to that system.
\citet{carey:2009_origin} argues that what I am calling the signature
limits of object indexes in adults are related to signature limits on
infants’ abilities to track briefly occluded objects.
Scholl 2007, figure 4
To illustrate, a moment ago I mentioned that one signature limit of
object indexes is that featural information sometimes fails to influence how objects are assigned in ways that seem quite dramatic.
Carey and Xu 2001, figure 3
There is evidence that, similarly, even 10-month-olds will sometimes
ignore featural information in tracking occluded objects
\citep{xu:1996_infants}.%
\footnote{
This argument is complicated by evidence that infants around 10 months of age do not always fail
to use featural information appropriately in representing objects as persisting
\citep{wilcox:2002_infants}.
In fact \citet{mccurry:2009_beyond} report evidence that even five-month-olds can make use of
featural information in representing objects as persisting \citep[see also][]{wilcox:1999_object}.
%they use a fringe and a reaching paradigm. NB the reaching is a problem for the simple interpretation of looking vs reaching!
% NB: I think they are tapping into motor representations of affordances.
Likewise, object indexes are not always updated in ways that amount to ignoring featural
information \citep{hollingworth:2009_object,moore:2010_features}.
It remains to be seen whether there is really an exact match between the signature limit on
object indexes and the signature limit on four-month-olds’ abilities to represent objects as
persisting.
The hypothesis under consideration---that infants’ abilities
to track briefly occluded objects depend on a system of
object indexes like that which underpins multiple object tracking or
object-specific preview benefits---is a bet on the match being exact.
}
Xu and Carey 1996, figure 4
\emph{The CLSTX conjecture}
Five-month-olds’ abilities to track occluded objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
object indexes.
\citep{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta}.
The CLSTX conjecture:
Five-month-olds’ abilities to track briefly unperceived objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
a system of object indexes.
Leslie et al (1989); Scholl and Leslie (1999); Carey and Xu (2001)
(‘CLSTX’ stands for Carey-Leslie-Scholl-Tremoulet-Xu \citep[see][]{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta})
While I wouldn’t want to suggest that the evidence on siganture limits is decisive, I think it
does motivate considering the hypothesis and its consequences. In what follows I will assume the
hypothesis is true: infants’ abilities to track briefly occluded objects depend on a system of
object indexes.

Core Knowledge vs Object Indexes
\section{Core Knowledge vs Object Indexes}
Consider the conjecture that infants’ abilities concerning physical objects are
characterised by the Principles of Object Perception because infants’ abilities
are a consequence of the operations of a system of object indexes.
If this conjecture is true, should we reject the claim that infants have a core
system for physical objects?
Or does having a system of object indexes whose operations are characterised by the Principles of
Object Perception amount to having core knowledge of those principles?
\emph{Outstanding problem}
Since having core knowledge of objects does not imply having knowledge knowledge of objects, how
can the emergence in development of knowledge of simple facts about particular physical objects be
explained?
What is the role of core knowledge of objects, and what other factors might be involved?
Let’s consider some consequences of the CLSTX conjecture.
\emph{The CLSTX conjecture}
Five-month-olds’ abilities to track occluded objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
object indexes.
\citep{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta}.
The CLSTX conjecture:
Five-month-olds’ abilities to track briefly unperceived objects
are not grounded on belief or knowledge:
instead
they are consequences of the operations of
a system of object indexes.
Leslie et al (1989); Scholl and Leslie (1999); Carey and Xu (2001)
(‘CLSTX’ stands for Carey-Leslie-Scholl-Tremoulet-Xu \citep[see][]{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta})
We saw this quote in the first lecture ...
‘if you want to describe what is going on in the head of the child when it has a few words which it utters in appropriate situations, you will fail for lack of the right sort of words of your own.
‘We have many vocabularies for describing nature when we regard it as mindless, and we have a mentalistic vocabulary for describing thought and intentional action; what we lack is a way of describing what is in between’
(Davidson 1999, p. 11)
Actually we don’t lack a way of describing what is in between.
We already have it.
We were simply not aware of it because we hadn’t thought carefully enough
about the representations and processes involved in perception and action.
The discovery that the principles of object perception characterise the operation of
object-indexes doesn't mean we have met the challenge exactly.
We haven't found a way of describing the processes and representations that underpin infants'
abilities to deal with objects and causes.
However, we have reduced the problem of doing this to the problem of characterising how
some perceptual mechanisms work.
And this shows, importantly, that understanding infants' minds is not something different from
understanding adults' minds, contrary to what Davidson assumes.
The problem is not that their cognition is half-formed or in an intermediate state.
The problem is just that understanding perception requires science and not just intuition.
What is the relation between infants' competencies with objects and adults'?
Is it that infants' competencies grow into more sophisticated adult competencies?
Or is it that they remain constant throught development, and are supplemented by quite
separate abilities?
The identification of the Principles of Object Perception with object-indexes suggests that
infants' abilities are constant throughout development.
They do not become adult conceptual abilities; rather they remain as perceptual systems
that somehow underlie later-developing abilities to acquire knowledge.
Confirmation for this view comes from considering that there are discrepancies in adults'
performances which resemble the discrepancies in infants between looking and action-based
measures of competence ...
[This links to unit 271 on perceptual expectations ...]
‘Just as humans are endowed with multiple, specialized perceptual systems, so we are endowed with multiple systems for representing and
reasoning about entities of different kinds.’
Carey and Spelke, 1996 p. 517

‘core systems are
- largely innate
- encapsulated
- unchanging
- arising from phylogenetically old systems
- built upon the output of innate perceptual analyzers’
(Carey and Spelke 1996: 520)
representational format: iconic (Carey 2009)
Which of these features are features of a system of object indexes?
‘there is a third type of conceptual structure,
dubbed “core knowledge” ...
that differs systematically from both
sensory/perceptual representation[s] ... and ... knowledge.’
Carey, 2009 p. 10
Sometimes when you’re looking for a theory, less is more.
Consider a crude, but hopefully very familiar picture of the adult mind.
The mind has different bits, and these are to an interesting extent independent of each other.
And there are at least three kinds of state, epistemic, motoric and perceptual.
Crude Picture of the Mind
- epistemic
(knowledge states) - broadly motoric
(motor representations of outcomes and affordances) - broadly perceptual
(visual, tactual, ... representations; object indexes ...)
These three kinds of state are not inferentially integrated.
They can also come apart in the sense that there can be multiple
representations in you simultaneously which can’t all be correct.
For example, there can be discrepancies between your knowledge of
a physical object’s location and where your perceptual systems represent it as being.
Given this crude picture, we might guess that a similar distinction applies to
infants’ minds.
Then we can ask, Which kind of representation does
their abilities to track briefly occluded objects involve?
We know it isn’t knowledge because this view generates incorrect predictions.
We also know it isn’t motoric, because motor representations depend on
possibilities for action and when an object is occluded by a barrier which
prevents action, it becomes impossible to act on the object.
And, on the face of it, the representation cannot be perceptual.
After all, in most of the experiments there is only visual information an occluded object
is not providing visual information about its location.
(Interestingly, infants’ problem with searching for occluded objects is not simply caused
by an absence of perceptual information concerning the object.
(\citeauthor{moore:2008_factors} has a toy make a noise continuously:
they found that eight-month-olds failed to search for a toy irrespective
of whether it made a noise \citep[Experiment 2]{moore:2008_factors}.)
So we seem to have a problem ... this was the attraction of invoking something
exotic like core knowledge
But we should reconsider the possibility that infants’ abilities to track briefly
occluded objects do indeed depend on perceptual information because there are some
broadly perceptual representations that do can specify the locations of occluded objects ...
... namely, object indexes.
Left half:
The Core Knowledge View
Infants, like most adults, do not know the principles of object perception; but they have core knowledege of them.
right_half:
The CLSTX conjecture
The principles of object perception characterise how a system of object indexes should work.
Infants’ (and adults’) object indexes track objects through occlusion.
Five-month-olds do not know the location of an occluded object.
Five-month-olds can have metacognitive feelings caused by discrepancies in its location.
‘CLSTX’ stands for Carey-Leslie-Scholl-Tremoulet-Xu \citep[see][]{Leslie:1998zk,Scholl:1999mi,Carey:2001ue,scholl:2007_objecta}
Are these two views compatible?
I think we had better characterise core knowledge in such a way that they
turn out to be true!